
이번에 간단하게 IntelliJ에서 Python 을 설치하고 크롤링 예제를 실행시켜보려한다.
1. Python 설치
https://www.python.org/downloads/
Download Python
The official home of the Python Programming Language
www.python.org
사이트에 접속하여 최신버전 Python을 다운 받습니다.
다운받고 아래 실행파일을 실행해줍니다.
실행이 완료된다면 다음같은 이미지로 실행이 될겁니다.
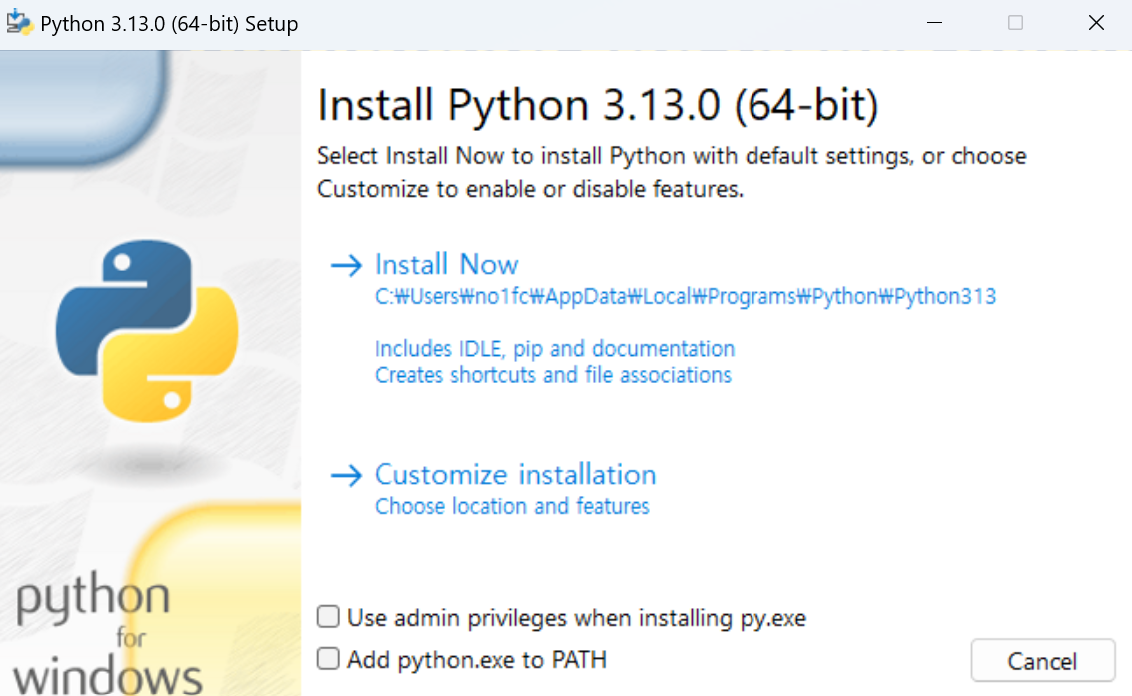
close가 나올때까지 설치를 진행하면 Python 설치는 완료됩니다.
2. IntelliJ 플러그인 설치
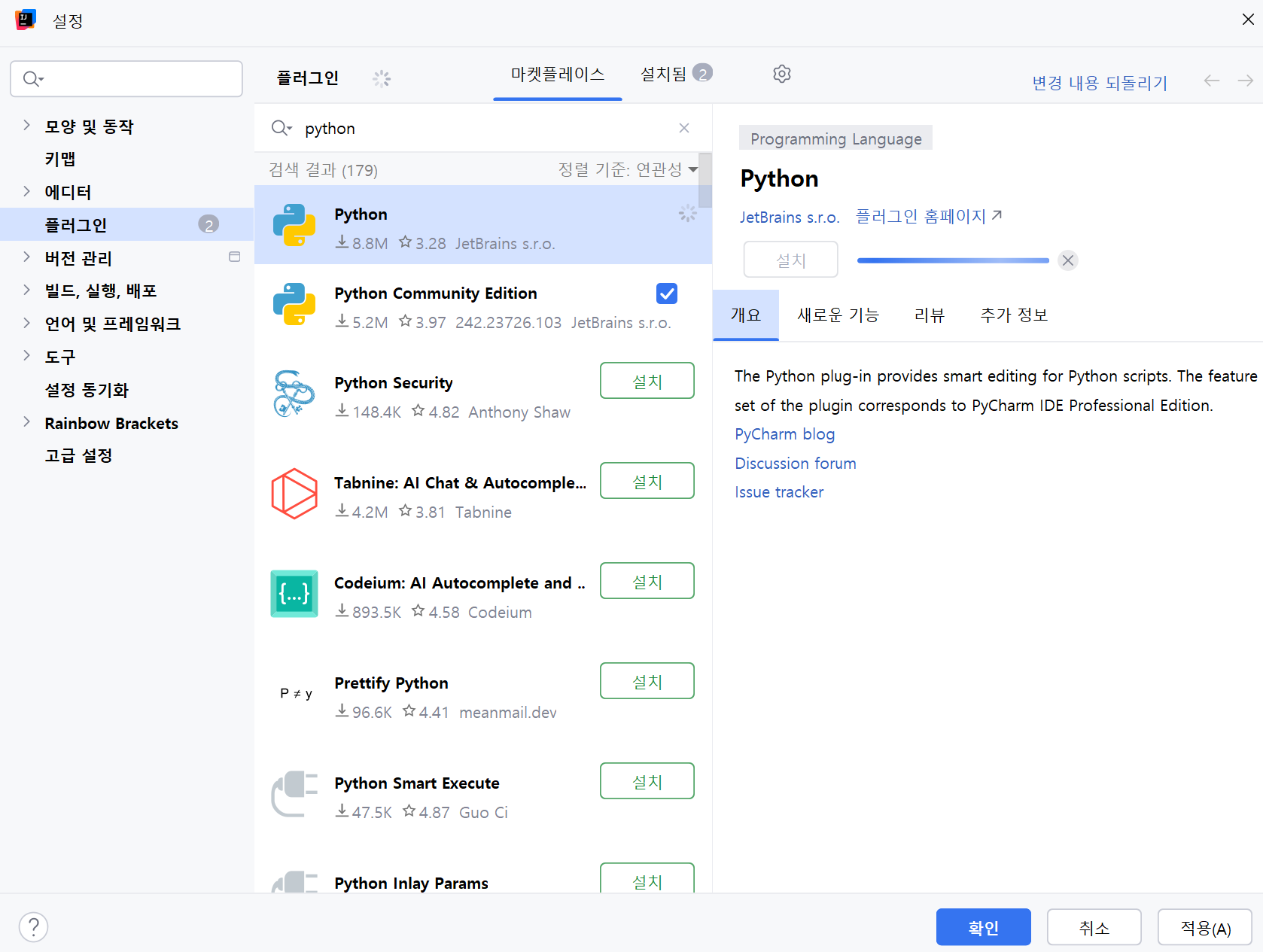
IntelliJ 플러그인 -> 마켓플레이스 -> Python 검색
Python 플러그인을 설치하고 IntelliJ를 재실행합니다.
3. Python 프로젝트 생성
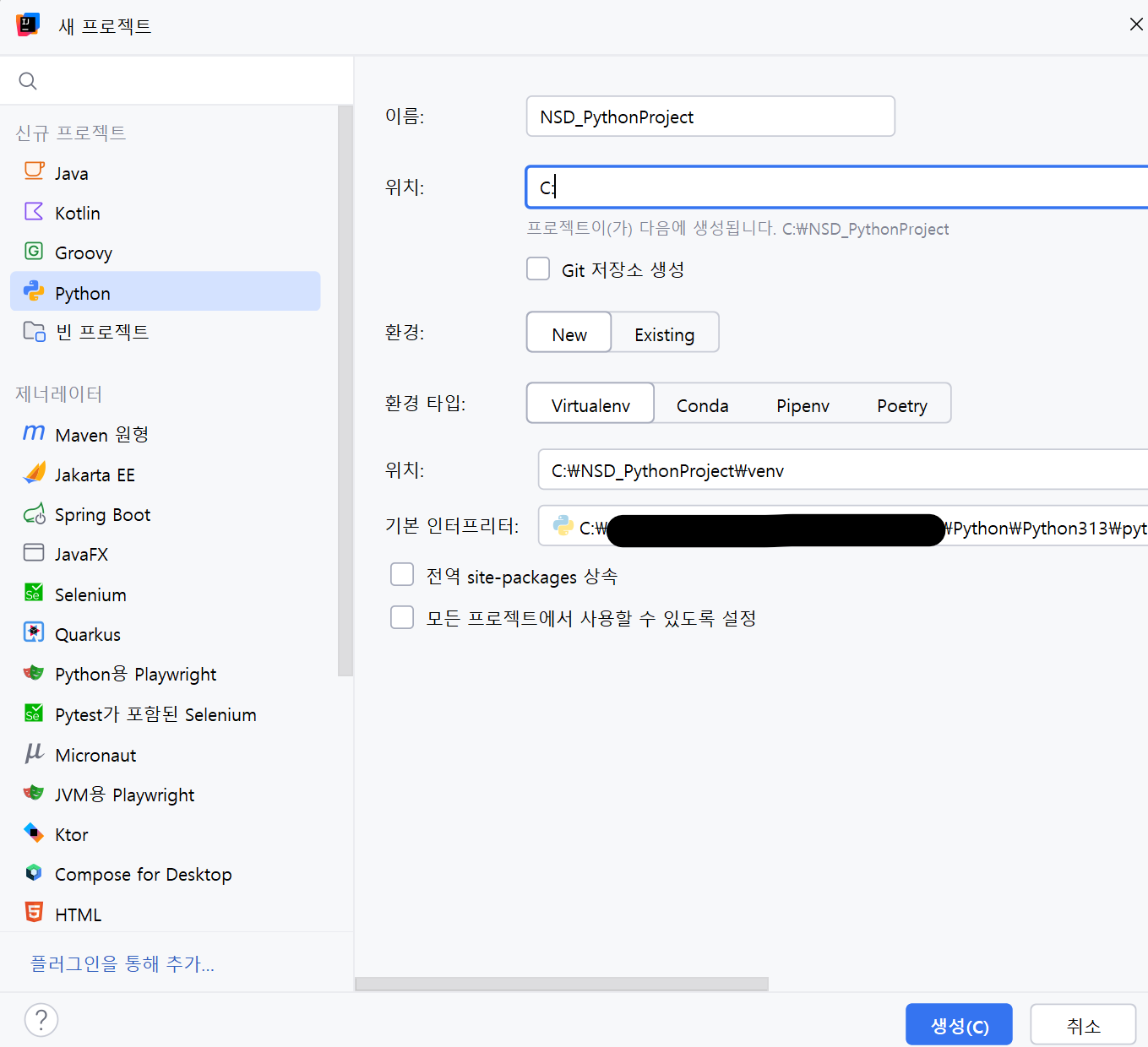
폴더를 생성하고 생성한 폴더로 위치를 지정해줍니다.
환경타입은 Virtualenv 로 설정합니다.
Virtualenv 는 각각의 프로젝트에 독립적인 Python 환경을 제공하는 도구이다.
개인 PC OR 서버에 별도 Python 환경이 구성되지 않았다면 대부분 Virtualenv 를 사용한다.
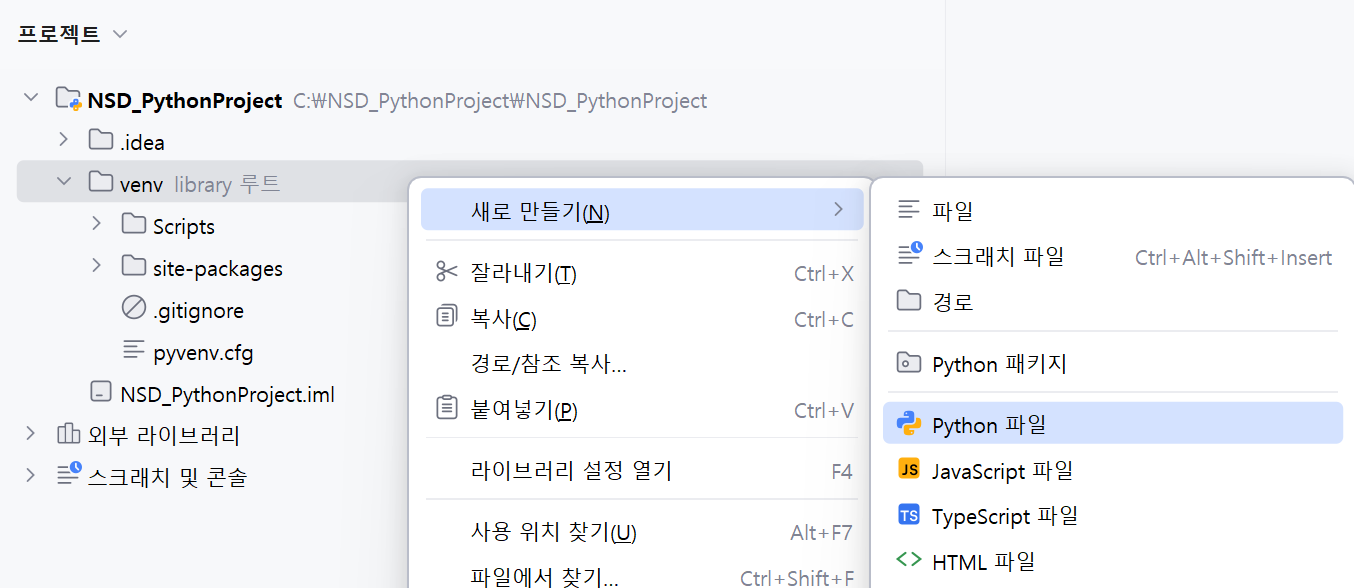
프로젝트 -> venv -> 새로 만들기 -> Python 파일 생성
웹 크롤링하기전 라이브러리를 다운로드합니다.
pip install requests beautifulsoup4IntelliJ 터미널에 위 코드를 실행하면 다운로드됩니다.
완료한다면 아래 예제코드로 크롤링을 해볼 수 있습니다.
import requests
from bs4 import BeautifulSoup
# 크롤링할 링크
url = "https://news.naver.com/section/105"
# 크롤링할 내용(select)를 입력
soupSelect = "li > div > div > div.sa_text > a > strong"
# URL(Naver 뉴스)로 응답을 받기 위해 requests.get() 메서드 사용
response = requests.get(url)
# BeautifulSoup 객체를 생성해 HTML 파싱
soup = BeautifulSoup(response.text, "html.parser")
# 지정한 CSS 셀렉터를 사용해 제목을 추출
headlines = soup.select(soupSelect)
# headlines가 비어있지 않다면
if headlines:
# 데이터 하나씩 Text 값 추출
for headline in headlines:
print(headline.text.strip())
# 만약 없다면
else:
# 로그를 출력하여 비어있다고 알려줌
print("비어있는 select 입니다.")
아래는 실행 결과이다.
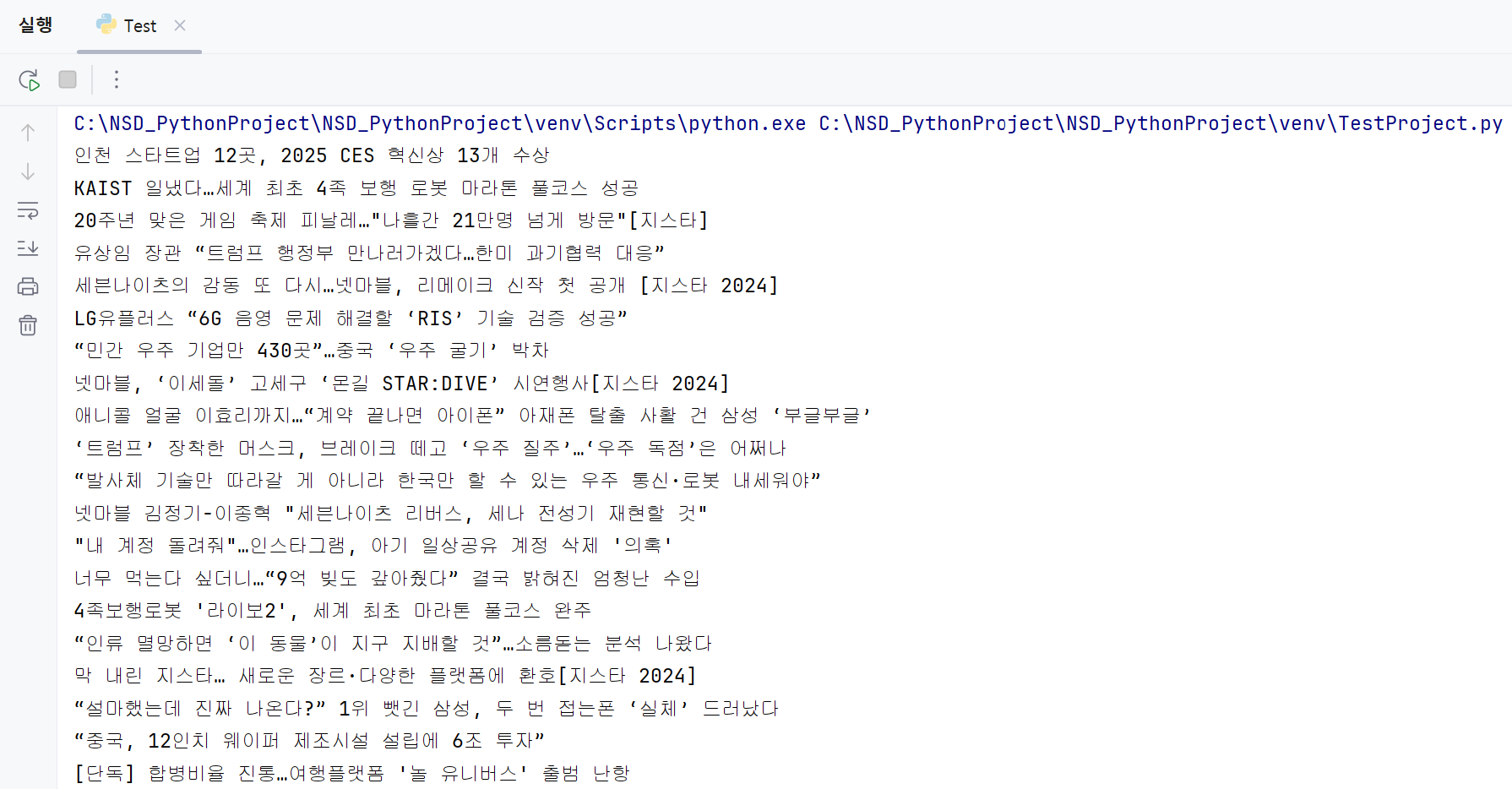
Python에 대한 이론은 아직 잘 모르지만
예제 코드를 보니 다른 언어와는 확연히 다르다는 느낌이 많이든다.
'추가 공부 > Python' 카테고리의 다른 글
| [Python] Numpy 기초 (0) | 2024.11.25 |
|---|---|
| [Python] 연산자 (2) | 2024.11.23 |
| [Python] 변수와 자료형 (0) | 2024.11.22 |
| [Python] 기본 자료형 (0) | 2024.11.22 |
| [Python] 공부 전 Python을 알아보자. (2) | 2024.11.17 |
이번에 간단하게 IntelliJ에서 Python 을 설치하고 크롤링 예제를 실행시켜보려한다.
1. Python 설치
https://www.python.org/downloads/
Download Python
The official home of the Python Programming Language
www.python.org
사이트에 접속하여 최신버전 Python을 다운 받습니다.
다운받고 아래 실행파일을 실행해줍니다.
실행이 완료된다면 다음같은 이미지로 실행이 될겁니다.
close가 나올때까지 설치를 진행하면 Python 설치는 완료됩니다.
2. IntelliJ 플러그인 설치
IntelliJ 플러그인 -> 마켓플레이스 -> Python 검색
Python 플러그인을 설치하고 IntelliJ를 재실행합니다.
3. Python 프로젝트 생성
폴더를 생성하고 생성한 폴더로 위치를 지정해줍니다.
환경타입은 Virtualenv 로 설정합니다.
Virtualenv 는 각각의 프로젝트에 독립적인 Python 환경을 제공하는 도구이다.
개인 PC OR 서버에 별도 Python 환경이 구성되지 않았다면 대부분 Virtualenv 를 사용한다.
프로젝트 -> venv -> 새로 만들기 -> Python 파일 생성
웹 크롤링하기전 라이브러리를 다운로드합니다.
pip install requests beautifulsoup4IntelliJ 터미널에 위 코드를 실행하면 다운로드됩니다.
완료한다면 아래 예제코드로 크롤링을 해볼 수 있습니다.
import requests
from bs4 import BeautifulSoup
# 크롤링할 링크
url = "https://news.naver.com/section/105"
# 크롤링할 내용(select)를 입력
soupSelect = "li > div > div > div.sa_text > a > strong"
# URL(Naver 뉴스)로 응답을 받기 위해 requests.get() 메서드 사용
response = requests.get(url)
# BeautifulSoup 객체를 생성해 HTML 파싱
soup = BeautifulSoup(response.text, "html.parser")
# 지정한 CSS 셀렉터를 사용해 제목을 추출
headlines = soup.select(soupSelect)
# headlines가 비어있지 않다면
if headlines:
# 데이터 하나씩 Text 값 추출
for headline in headlines:
print(headline.text.strip())
# 만약 없다면
else:
# 로그를 출력하여 비어있다고 알려줌
print("비어있는 select 입니다.")
아래는 실행 결과이다.
Python에 대한 이론은 아직 잘 모르지만
예제 코드를 보니 다른 언어와는 확연히 다르다는 느낌이 많이든다.
'추가 공부 > Python' 카테고리의 다른 글
| [Python] Numpy 기초 (0) | 2024.11.25 |
|---|---|
| [Python] 연산자 (2) | 2024.11.23 |
| [Python] 변수와 자료형 (0) | 2024.11.22 |
| [Python] 기본 자료형 (0) | 2024.11.22 |
| [Python] 공부 전 Python을 알아보자. (2) | 2024.11.17 |